大模型学习
【硅谷101 138期】
五步
- ChatGPT总结,全局理解,记录在spreadsheet
- Audible/speechify听
- spreadsheet复习,费曼法自问
- chatgpt提问,作比较、扩展延申到相关的问题和领域
- 用RAG+GPT API做research
优化后步骤
- chatGPT总结,以markdown记录在自己的博客
- 使用手机自带,辅助朗读功能听
- 使用脑图记录知识点脉络。费曼法自问
- chatgpt提问,作比较、扩展延申到相关的问题和领域
- 用RAG+GPT API做research(带调研步骤)
检索增强生成(RAG,Retrieval Augmented Generation)
RAG 对大语言模型(Large Language Model,LLM)的作用,就像开卷考试对学生一样。在开卷考试中,学生可以带着参考资料进场,比如教科书或笔记,用来查找解答问题所需的相关信息。开卷考试的核心在于考察学生的推理能力,而非对具体信息的记忆能力。
在 RAG 中,事实性知识与 LLM 的推理能力相分离,被存储在容易访问和及时更新的外部知识源中,具体分为两种:
- 参数化知识(Parametric knowledge): 模型在训练过程中学习得到的,隐式地储存在神经网络的权重中。
- 非参数化知识(Non-parametric knowledge): 存储在外部知识源,例如向量数据库中。
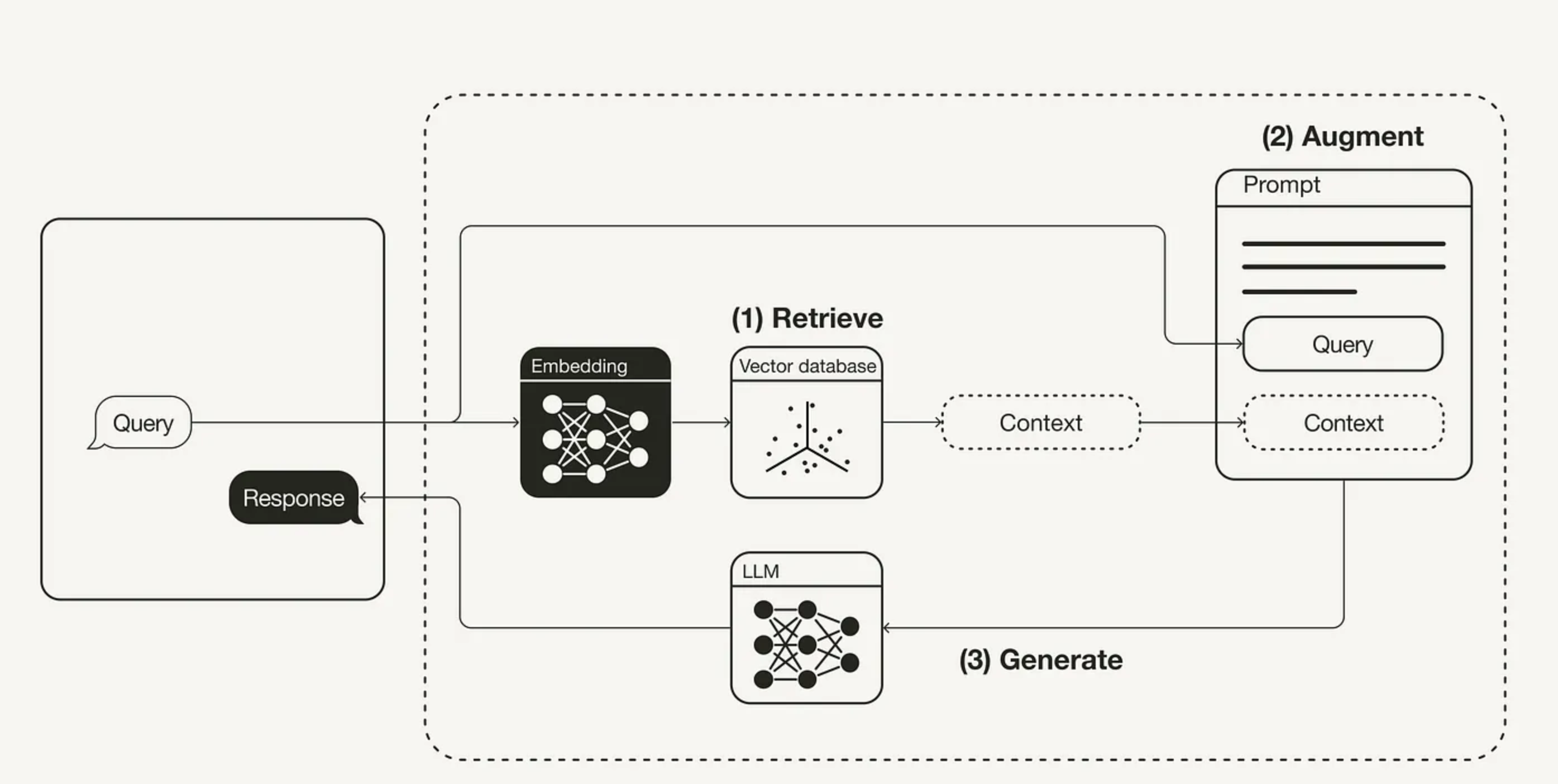
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。



